

Redis
Redis是目前互联网项目开发过程中,使用范围最广的存储中间件之一,关于Redis的技术使用点包含了缓存、分布式锁、限流等。算是一个标准的后端必须要去学习了解的一项技术。
选型
最初关于缓存中间件的选型会存在Redis和Memcached两款,关于两款中间件的特点我会在下面用表格罗列。关于这两款中间件其实并没有一个孰优孰劣的概念,要明确是适合业务的技术才是好技术,撇开业务单谈技术都是耍流氓。
| Redis | Memcached | |
|---|---|---|
| 数据结构 | String、Hash、List、Set、SortedSet | String(单纯的Key/Value结构) |
| 持久化 | RDB(全量存储)、AOF(日志存储) | - 不支持 - |
| 主从同步 | Master/Slave | - 不支持 - |
| 集群 | Redis cluster | - 不支持 - |
| 效率 | 由于Redis使用的是单线程,以及复杂的元数据结构,在存储效率上低于Memcached | - |
基于以上几点分析,若是业务内只是需求基础的String类型Get/Set,那么Memcached完全可以胜任这项工作,但若是业务有更复杂的需求,需要做主从同步,甚至是集群以保持一个高可用,需要能够在服务器Down了之后能够对数据进行恢复,那么Redis无疑是更佳的选择。
缓存
缓存是
Redis的主要功能之一,在有大流量访问数据时,缓存能为数据库分担很大一部分压力。说到这就不得不提及使用缓存所要尽量避免的三大问题 穿透、击穿、雪崩。
缓存穿透
缓存穿透在概念上很好理解,即请求者发送了非法的参数请求到应用,应用会先去缓存查询一遍数据是否被缓存,但由于参数非法,这条数据永远也不会被缓存在Redis中,于是应用会去查询数据库,但数据库里依旧不会存在非法数据,所以返回空。当这种非法请求全部打到数据库上的时候,数据库的情况也可想而知了。
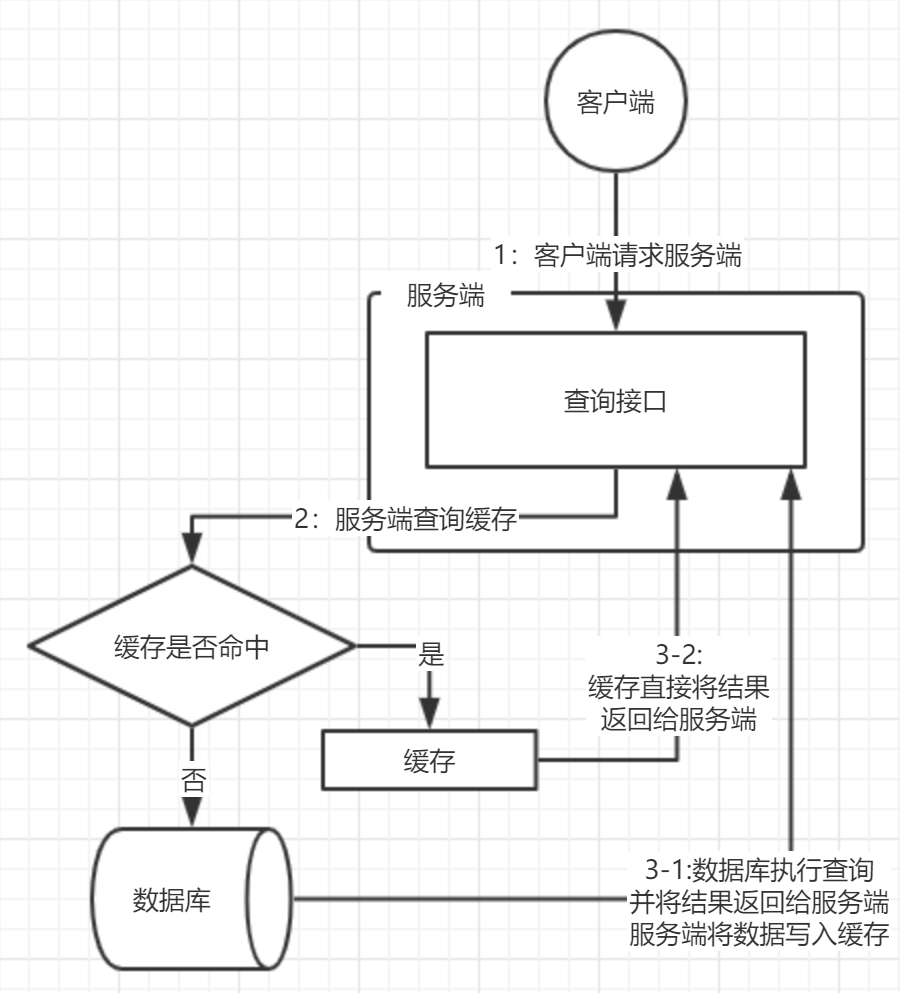
这是一套相对标准的请求流程图,为什么说相对标准,因为该流程图内还没考虑到缓存数据同步的问题,这方面要说的内容也有很多,下回有机会再说。
面对这张图,假设数据库存在一张表T,主键ID自增,目前表内有100条数据,服务端提供查询接口,查询参数为ID,目前一百条数据都存在于缓存。现有一个用户,不断地向接口请求ID = -1的数据,结果当然是缓存不命中,直接查询数据库,数据库没有对应数据,但也扛不住请求压力,自然就挂了。
当然现在有小可爱肯定就会说:“那我在接口处做一个判断,判断ID小于0就直接返回不就行了嘛。”
既然是非法参数请求,自然是能从接口处拦截住并返回的,但是如果只判断了ID < 0,那如果那个用户请求的ID参数大于100了呢?所以对于服务来说,只要是未在数据区间内的请求,都可以说是缓存穿透。至于缓存穿透的解决办法,可以考虑在接口处使用布隆过滤器进行参数校验。至于布隆过滤器的原理和实现,如果有机会的话之后再说吧。
缓存击穿
缓存击穿是指在有大量并发请求同一个Key时,Key的失效时间到了,此时大量的并发会全部引向数据库,之后数据库瞬间就挂掉了。
既然知道原因了那么解决办法也就很明朗了,一是给该数据加上锁,涌入的第一个请求会去数据库里取到数据,之后存进缓存,而之后的请求再去缓存里取就没问题了。
伪码:
1 | Object getData(String key){ |
至于第二种办法,就是不给该数据设置过期时间,只更新替换不删除就可以了。
缓存雪崩
缓存雪崩其实和缓存击穿类似,但区别在于缓存击穿的击穿点是一条数据,而缓存雪崩是指有大量数据同时过期,导致请求不命中缓存,全部压到了数据库上,数据库就顶不住了。
处理方法和缓存击穿也类似,第一种方法就是设置该数据永不过期,只更新,不替换。而第二种方法就是给数据设置的过期时间加上一个随机值以保证大量数据不会在同一时间过期。
思路:SET key Value 过期时间 + Math.Random() * 10000
分布式锁
由于现在分布式系统、SOA、微服务将原有的一体式系统剥离了开来,在提高了系统可用性的同时也带来可一致性的问题。在分布式系统中,要实现对同一资源的同步访问,就需要用到分布式锁,分布式锁的实现方式有很多,这边就主要说说关于
Redis的实现。
分布式锁的实现基于Redis的SETNX命令。
Redis官网对SETNX的描述如下:Setkeyto hold stringvalueifkeydoes not exist. In that case, it is equal to SET. Whenkeyalready holds a value, no operation is performed. SETNX is short for “SET if Not eXists”.
即当Key不存在时,将Key的值设置为Value,如果Key已存在,则什么都不会改变。当设值成功时,Redis会返回1,反之则返回0。
根据以上特性,如何作为分布式锁的思路已经很清楚了,各个服务在要对资源进行同步访问之前,先操作Redis,若是存值成功,则获取锁,在操作完成之后删除键以释放锁。反之,可进行自旋或其它操作。
伪码:
1 | if(setNX(key, 1) == 1){ |
通过以上代码,就可以对资源在分布式系统中进行加锁操作。但是在实际开发过程中,我们还需要考虑更多的情况。我们考虑这么一种情况:某个服务在对资源进行加锁之后挂了,锁并没有得到释放,那么就算服务重启了,进行对资源的重新加锁,发现Key已存在,获取锁失败。
面对这种情况,我们就需要考虑对该Key设置超时,在超时之后Key自动失效,即锁会被释放,可以被其它服务重新获取锁权限。由于SETNX和EXPIRE是分开操作的,无法保证一个命令的原子性,好在SET命令在Redis2.6.12版本后添加了NX和XX参数,使得我们可以通过SET命令来完成该原子操作。
伪码:
1 | if(set(key, anyValue, 10, NX) == 1){ |
以上代码能解决获取锁的服务挂了之后锁被永久占用的情况,但是聪明的孩子应该已经看出来问题了。若是获取锁的服务在十秒内完成不了对应的操作怎么办?那锁会直接被释放,然后被其它服务锁获取,此时就会有两个服务同时操作资源,锁被打破。至于解决办法呢,延长锁的过期时间?要是延长了也完成不了对应操作呢。Shaw这边有一种比较取巧的做法。
伪码:
1 | if(set(key, anyValue, 10 NX) == 1){ |
根据上边的代码,我们再以之前那些问题带入看看能不能解决。
- 锁被获取后线程挂了,锁被永久占有无法得到释放
- 通过加锁时设置的过期时间解决锁无法释放的问题
- 加锁步骤
SETNX、EXPIRE非原子性操作,不能解决服务器挂了锁无法释放的问题- 通过
SET key value [EX seconds] [PX milliseconds] [NX|XX]命令完成原子性加锁和设置锁超时
- 通过
- 加锁后无法确定服务具体执行时间导致锁提前释放问题
- 在服务获取锁之后启动一个定时执行的守护线程,在锁快到期时延长锁的过期时间,保证锁的持有。在该情况下,即使获获取了锁的服务挂了,由于没有了守护线程对锁的过期时间延长,锁在到了过期时间后仍会被释放,然后重新被其它服务争抢。
到此为止,Redis的分布式锁设置过程,才算是近乎完整。但具体的实践操作,还需要根据实际业务开发的情况而定。
小结
Redis相关,我觉得值得一写的点目前就是这些了,要是日后还有其它想补充的就再靠之后的文字去补了,关于Redis,其实我觉得目前行业内应用它有点像万精油,就是很多东西都能做但是很多东西都不是很完善,所以在项目开发进行技术选型的时候,还是希望进行综合考虑去定夺一项技术或者一项中间件的选用。